
Il 17 aprile sono salito sul palco del Global Azure Veneto con un caro amico. Ci unisce la passione per quello che facciamo e per la tecnologia che usiamo ogni giorno: lui è un Chief Network Architect, io sono un Data Solution Architect. Competenze diverse, spesso vissute in reparti separati che faticano a parlarsi.
È esattamente questa separazione il motivo per cui abbiamo costruito questa sessione insieme. Troppo spesso chi progetta architetture dati non conosce l’infrastruttura di rete su cui girano, e chi progetta l’infrastruttura non ha piena consapevolezza delle esigenze di una piattaforma dati enterprise. Il risultato lo vediamo nei progetti: decisioni di rete prese senza considerare il pattern serverless, o architetture dati progettate senza sapere come funziona il Private Endpoint di Databricks. Ognuno ottimizza il suo pezzo, il sistema nel suo insieme resta fragile.
Abbiamo voluto fare il contrario: unire le competenze fin dalla progettazione, costruire un’architettura enterprise completa dove l’infrastruttura comprende le esigenze della soluzione dati e la soluzione dati si appoggia su una rete progettata per reggerla. Preparare la sessione è stato uno dei lavori più interessanti degli ultimi mesi. Ognuno ha messo in campo il proprio dominio, ci siamo messi in discussione a vicenda, e il risultato finale è migliore di quello che avremmo prodotto separatamente.
Di cosa abbiamo parlato
La sessione era divisa in tre aree: il modello architetturale di Databricks (Control Plane vs Compute Plane, Classic vs Serverless), le ultime novità di Unity Catalog in Public Preview, e l’architettura enterprise di rete con VNet Injection e NCC.
Abbiamo aperto chiarendo una distinzione che sembra ovvia ma in pratica non lo è: cosa sta nel Control Plane di Databricks (Web Application, Unity Catalog, Compute Orchestration, Queries & Code) e cosa sta nel Compute Plane del cliente. E soprattutto, la differenza tra Classic Compute e Serverless Compute, perché i due modelli hanno implicazioni di rete completamente diverse. Con il Classic Compute i nodi girano nella tua VNet, hai pieno controllo su routing, NSG e firewall. Con il Serverless l’infrastruttura è gestita da Databricks, non esiste VNet Injection, e il modello di connettività privata verso i tuoi dati funziona in modo differente. Partire da questa distinzione era fondamentale per dare senso a tutto quello che abbiamo mostrato dopo.
Il filo conduttore era la sinergia tra le due discipline: un’architettura dati che non conosce la rete su cui gira è incompleta, e una rete progettata senza considerare le esigenze del compute serverless lascia buchi aperti nel momento sbagliato.
Unity Catalog: modello e ultime novità
Abbiamo dedicato una parte della sessione a Unity Catalog, partendo dal modello: la gerarchia Metastore → Catalog → Schema → Object con ereditarietà dei privilegi, il privilege model fine-grained fino a colonna e riga, lineage automatico e audit integrato. Una panoramica che serviva da base comune prima di entrare sulle funzionalità più recenti.
La parte che ha interessato di più erano le novità in Public Preview: Governed Tags, Tag Policy con allowed values e assign permissions, e le ABAC Policy (Row Filter e Column Mask). Ne avevo già scritto in un post precedente. In sessione ho mostrato il pattern che uso: un governed tag pii per le colonne sensibili, una Column Mask che usa IS_ACCOUNT_GROUP_MEMBER() per mostrare il valore reale solo a pii_readers e account_admins, e una Row Filter Policy per business unit che restringe la visibilità delle righe in base al gruppo Databricks dell’utente. Niente viste apposite, niente script manuali.
Architettura Classic Compute: i dettagli che contano
Sul fronte di rete, abbiamo presentato il pattern hub-and-spoke enterprise con VNet Injection.
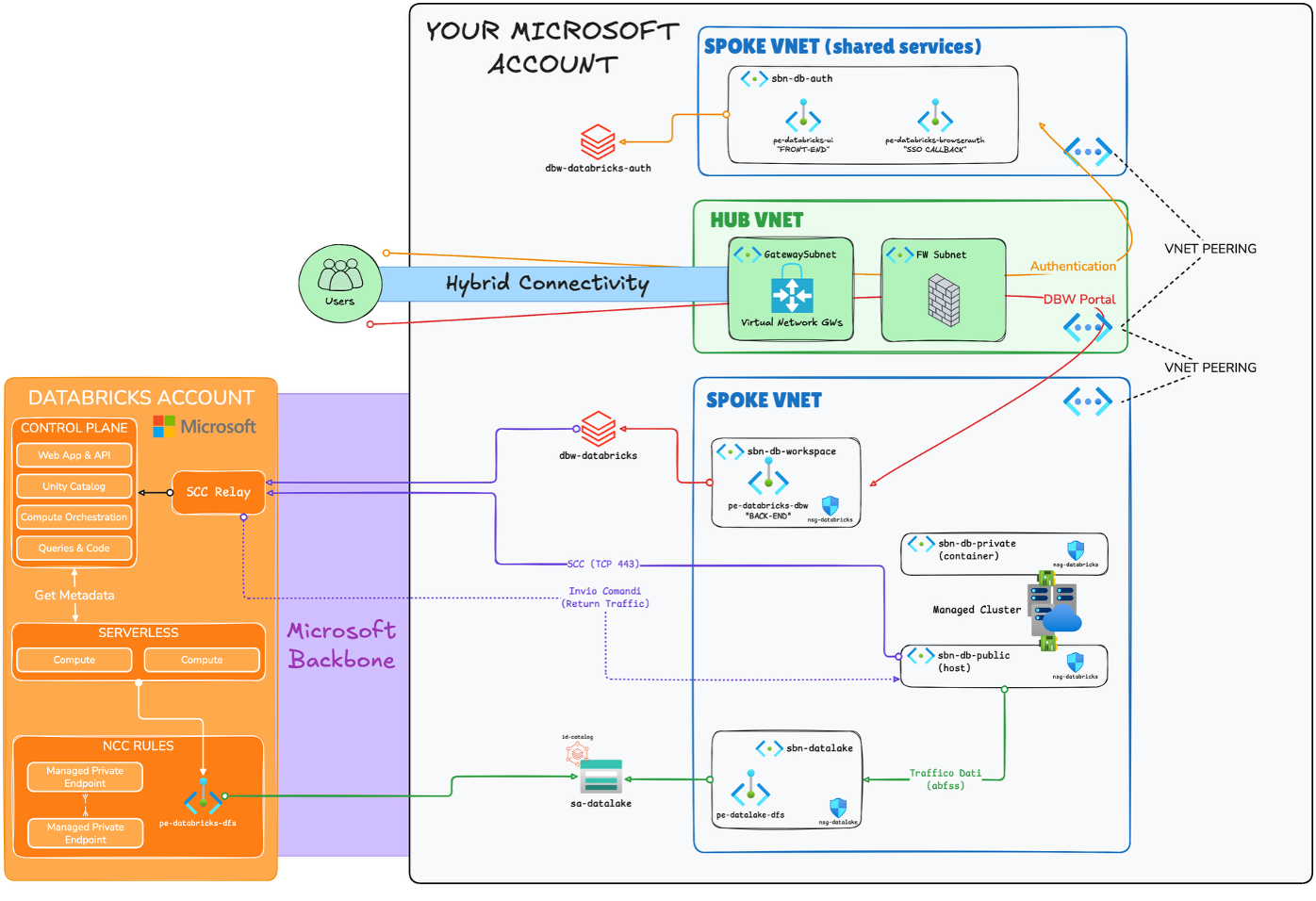
Nota sul diagramma: abbiamo scelto volutamente di rappresentare solo i flussi outbound, ovvero la direzione in cui ogni connessione viene instaurata. Il traffico di ritorno viaggia sullo stesso canale ed è implicito. Includere entrambe le direzioni avrebbe reso il disegno confuso e difficile da leggere, oscurando i pattern architetturali che volevo evidenziare.
Il grafico mostra:
- Secure Cluster Connectivity (NPIP) con SCC Relay: i cluster non hanno IP pubblici e il canale di controllo TCP 443 parte sempre dal data plane verso il control plane, non il contrario.
- Private Endpoint di back-end nel workspace spoke per il sub-resource
databricks_ui_api, necessario perché l’SCC Relay raggiunga il control plane privatamente. - Private Endpoint di front-end in shared services per
databricks_ui_api(lato utenti) ebrowser_authenticationper il callback SSO di Entra ID. - Private Endpoint su ADLS Gen2 (
dfs) nel datalake spoke, con trafficoabfssche resta sul backbone Microsoft. - Azure Firewall nell’hub con UDR sulle subnet
hostecontainerper il traffico in uscita, con le eccezioni FQDN obbligatorie per Databricks.
Una cosa su cui mi piace soffermarmi ogni volta che parlo di VNet Injection (su Azure Databricks) è il naming delle subnet, perché crea sempre confusione. Databricks richiede due subnet delegate, chiamate ufficialmente host e container, ma nella documentazione e nel portale Azure le trovi anche come public e private. Il nome public è fuorviante: non significa che i nodi hanno IP pubblici. Con Secure Cluster Connectivity abilitato (che è la configurazione raccomandata), nessun nodo ha IP pubblici, né sulla host né sulla container.
La distinzione è funzionale, non di esposizione. Sulla subnet host (public) gira il nodo driver del cluster Spark, quello che coordina il job, comunica con il control plane via SCC Relay e interagisce con i servizi esterni. Sulla subnet container (private) girano i nodi executor/worker, quelli che eseguono i task distribuiti e si scambiano dati tra loro. In passato, prima di NPIP, il driver sulla host aveva effettivamente un IP pubblico per comunicare con il control plane. Oggi quel canale passa attraverso SCC su TCP 443 in uscita, e il nome “public” è rimasto come eredità storica. Vale la pena spiegarlo esplicitamente nel design, perché chi legge un diagramma con “public subnet” senza contesto tende a storcere il naso.
Serverless e NCC: il pattern che spesso viene disegnato male
Questa era la parte della sessione a cui tenevo di più, perché è il punto dove vedo i disegni architetturali sbagliati più spesso.
Quando si aggiunge il Serverless Compute (SQL Warehouse serverless, Jobs serverless, Lakeflow Pipelines) a un’architettura già progettata per i cluster classici, la domanda è: come fa il serverless a raggiungere ADLS Gen2, o il managed storage di Unity Catalog, in modo privato? Il serverless non sta nella tua VNet. Non puoi mettere un UDR, non puoi configurare un NSG. La VNet Injection non esiste per il serverless.
La risposta è NCC (Network Connectivity Configuration): una risorsa account-level di Databricks che governa la connettività in uscita del serverless compute plane. La parte importante è capire che NCC ha due modalità distinte:
- Stable egress IPs: Databricks assegna IP pubblici stabili da cui esce il serverless. Utile per allowlist su risorse che non supportano Private Link, non utile per la sicurezza vera.
- Private Endpoint Rules: crei una regola NCC che punta a una tua risorsa Azure. Databricks fa il provisioning dei Managed Private Endpoint nel serverless compute plane verso quella risorsa. Tu approvi la connection request lato Azure. Da quel momento il traffico passa sul backbone Microsoft, senza internet.
Il disegno corretto non è una freccia dal serverless allo storage account. È un Managed Private Endpoint nel serverless compute plane di Databricks che si connette via Microsoft backbone alla tua risorsa, con una connection request approvata da te nel portale Azure.
Su uno stesso storage account puoi quindi avere due private endpoint connection: quello che hai creato tu (per i cluster classici dal VNet injection) e quello gestito da Databricks via NCC (per il serverless). Stessa risorsa, due canali privati distinti.
Cosa porto a casa
Presentare questi argomenti è sempre utile per me. Costringerti a costruire un disegno architetturale che regge le domande di una platea tecnica ti porta a verificare dettagli che nella quotidianità dai per scontati.
La cosa che mi ha colpito di più nelle reazioni della sala è quanto sia ancora diffuso il pattern “faccio VNet Injection per i cluster classici, aggiungo il serverless più avanti”. Il “più avanti” non ha un design. NCC, PE rules, approvazione delle connections, le DNS zone che devono coprire anche il managed storage di UC: sono tutti pezzi che devono stare nel design iniziale, non nell’iteration successiva.
Grazie a chi è venuto, agli organizzatori del Global Azure Veneto per la cura nell’organizzazione. Ci vediamo alla prossima edizione.
Risorse