
Real-Time: Databricks vs Microsoft Fabric or Spark vs Kusto Databricks or Microsoft Fabric for building architectures for (Near) Real-Time data analysis?
This is a question that naturally arises when we consider building an architecture for managing streaming data on Microsoft Azure.
We are witnessing the evolution of modern data architectures, where we can observe a progressive convergence between batch and streaming paradigms, driven by the need to reduce “Time-to-Insight” and enable instant decision-making processes. In the current landscape, two platforms emerge as undisputed leaders in Azure, offering divergent architectural philosophies. Databricks is based on the Apache Spark engine and Lakehouse architecture, while Microsoft Fabric offers a unified SaaS ecosystem based on multiple specialised engines, including Kusto for Real-Time Intelligence.

Databricks: Spark Engine and Computational Flexibility
Databricks relies on Apache Spark Structured Streaming for real-time process management.
The predominant mode in Spark is Micro-batch (default). The system accumulates data for a defined trigger interval (e.g., 500 ms), schedules a job, processes the data, and updates the sinks. This approach ensures very high throughput and robust ‘exactly-once’ semantics, as the system can track read and write offsets accurately. However, micro-batch inherently introduces latency related to job scheduling and offset management, which historically limited responsiveness to sub-second latencies.
To overcome this limitation, Databricks takes us into the future, at the Data + AI Summit 2025 in San Francisco, announcing the new Real-Time Mode. This mode abandons traditional micro-batching in favour of continuous, asynchronous execution. Instead of launching discrete jobs, Spark launches long-running tasks that process data as soon as it arrives in the input buffer. Checkpointing and commits are handled asynchronously, decoupling persistence I/O from the logical processing flow. This allows for latencies in the tens of milliseconds, making Databricks competitive even for fraud detection scenarios.
Microsoft Fabric: Kusto Engine and Indexing
Microsoft Fabric takes a radically different approach with its Real-Time Intelligence workload.
At its heart is the Kusto engine (originally developed with Azure Data Explorer). Kusto is not a general-purpose processing engine like Spark, but a distributed analytical database optimised for append-only and high-concurrency queries. Its procedural nature allows complex queries to be built step by step. For streaming data, KQL offers a set of primitives for advanced analysis:
Time-Series Analysis: Functions such as make-series allow you to regularise time series data, creating continuous series ready for analysis.
Pattern Recognition: Plugins such as series_decompose_anomalies or series_periods_validate allow you to detect seasonal patterns or anomalies directly within the query, leveraging the engine’s indexing for instant responses.
From Engines to Architecture: A Comparison of Ecosystems
If the computing engine is the heart, the surrounding architecture is the skeleton that supports the solution. Here, the philosophical differences between the two platforms become apparent.
Azure Databricks
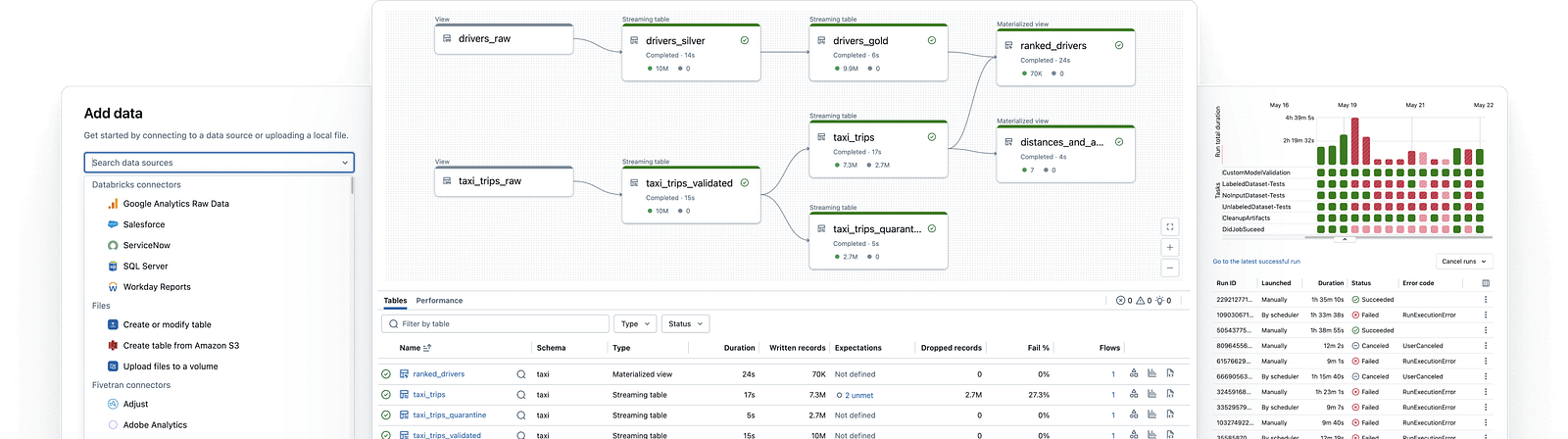
Databricks Lakeflow
With total control of Code-First in Databricks, the approach is engineering-centric. The platform offers maximum granular control through Databricks Lakeflow (and Delta Tables), allowing you to orchestrate complex streaming pipelines by writing native code in Python or SQL. Streaming flow management is simplified with the lakeflow framework:
Ingestion and Transformations: Leveraging the power of Spark Structured Streaming, data is processed and refined. Furthermore, using the declarative syntax of Spark Declarative Pipelines, we streamline the code and strengthen it by leveraging automatic checkpoint management.
from pyspark import pipelines as dp # create a streaming table @dp.table def customers_bronze(): return ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load("/Volumes/path/to/files") )Storage and Governance: Data will be stored in Delta Tables within the Unity Catalogue, which acts as a unified governance layer.
Microsoft Fabric

Microsoft Fabric: Real-Time HUB
The simplicity of the integrated SaaS Fabric responds with a Low-Code/No-Code philosophy geared towards ‘Real-Time Intelligence’. Here, the goal is to drastically reduce Time-to-Insight. The flow is linear and managed with different components:
- Ingestion: Eventstreams to capture data at source with the option of applying filters and transformations.
- Storage and Analysis: Data is conveyed to an Eventhouse based on KQL Database. Unlike Delta Tables, this storage is specifically optimised for queries on time series and high-frequency logs.
- Visualisation: The circle closes with Real-Time Dashboards, which allow data to be visualised after ingestion, bypassing the latency typical of dataset refreshes.
So, which platform should you choose?
There is no universal answer, nor is there an absolute winner. The choice between Databricks and Microsoft Fabric depends on the balance between the granularity of control you want and the ease of management you need. To facilitate this decision, I have summarised the comparison in two visual frameworks:
- A Feature Matrix, to analyse the pure technical differences.
- A Use Case Matrix, to identify which tool best suits your specific business scenario.

Feature Matrix

Use Case Matrix
Final Thoughts
I like to think of Databricks as the Formula 1 engine you need to assemble to win complex engineering races (ETL and ultra-low latency actions), while Fabric gives you a sports car with autopilot, ready to take you from raw data to dashboard in record time. What do you think? Let’s discuss this further in the comments.